Introduction to JavaScript Source Maps
Have you ever found yourself wishing you could keep your client-side code readable and more importantly debuggable even after you’ve combined and minified it, without impacting performance? Well now you can through the magic of source maps.
Basically it’s a way to map a combined/minified file back to an unbuilt state. When you build for production, along with minifying and combining your JavaScript files, you generate a source map which holds information about your original files. When you query a certain line and column number in your generated JavaScript you can do a lookup in the source map which returns the original location. Developer tools (currently WebKit nightly builds, Safari, Google Chrome, or Firefox 23+) can parse the source map automatically and make it appear as though you’re running unminified and uncombined files.
View a live demo Download the source files
The above demo allows you to right click anywhere in the textarea containing the generated source. Select “Get original location” will query the source map by passing in the generated line and column number, and return the position in the original code. Make sure your console is open so you can see the output.

Real world
Before you view the following real world implementation of Source Maps make sure you’ve enabled the source maps feature in either Chrome Canary or WebKit nightly by clicking the settings cog in the dev tools panel and checking the “Enable source maps” option. See screenshot below.

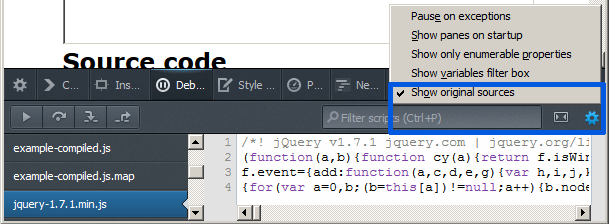
Firefox 23+ you can enable source maps via the cog in the debugger tab. Firefox 24+ will enable source maps by default. See screenshot below.
So… That Source Map query demo is cool and all but what about a real world use case? Take a look at the special build of font dragr at dev.fontdragr.com in Chrome Canary, WebKit nightly, Safari pre-release or Firefox 23+, with source mapping enabled, and you’ll notice that the JavaScript isn’t compiled and you can see all the individual JavaScript files it references. This is using source mapping, but behind the scenes actually running the compiled code. Any errors, logs and breakpoints will map to the dev code for awesome debugging! So in effect it gives you the illusion that you’re running a dev site in production.
Why should I care about source maps?
Right now source mapping is only working between uncompressed/combined JavaScript to compressed/uncombined JavaScript, but the future is looking bright with talks of compiled-to-JavaScript languages such as CoffeeScript and even the possibility of adding support for CSS preprocessors like SASS or LESS.
Source map support can be found in many compiled to JavaScript languages like Coffeescript and Typescript.
In the future we could easily use almost any language as though it were supported natively in the browser with source maps:
- CoffeeScript
- ECMAScript 6 and beyond
- SASS/LESS and others
- Pretty much any language that compiles to JavaScript
Take a look at this screencast of CoffeeScript being debugged in an experimental build of the Firefox console:
The Google Web Toolkit (GWT) has recently added support for Source Maps and Ray Cromwell of the GWT team did an awesome screencast showing source map support in action.
Another example I’ve put together uses Google’s Traceur library which allows you to write ES6 (ECMAScript 6 or Next) and compile it to ES3 compatible code. The Traceur compiler also generates a source map. Take a look at this demo of ES6 traits and classes being used like they’re supported natively in the browser, thanks to the source map. The textarea in the demo also allows you to write ES6 which will be compiled on the fly and generate a source map plus the equivalent ES3 code.

How does the source map work?
The only JavaScript compiler/minifier that has support, at the moment, for source map generation is the Closure compiler. (I’ll explain how to use it later.) Once you’ve combined and minified your JavaScript, alongside it will exist a sourcemap file. Currently, the Closure compiler doesn’t add the special comment at the end that is required to signify to a browsers dev tools that a source map is available:
//# sourceMappingURL=/path/to/file.js.map
This enables developer tools to map calls back to their location in original source files. Previously the comment pragma was //@ but due to some issues with that and IE conditional compilation comments the decision was made to change it to //#. Currently Chrome Canary, WebKit Nightly, Safari pre-release and Firefox 24+ support the new comment pragma. This syntax change also affects sourceURL.
X-SourceMap: /path/to/file.js.mapLike the comment this will tell your source map consumer where to look for the source map associated with a JavaScript file. This header also gets around the issue of referencing source maps in languages that don’t support single-line comments.

The source map file will only be downloaded if you have source maps enabled and your dev tools open. You’ll also need to upload your original files so the dev tools can reference and display them when necessary.
How do I generate a source map?
Like I mentioned above you’ll need to use the Closure compiler to minify, concat and generate a source map for your JavaScript files. The command is as follows:
java -jar compiler.jar
--js script.js
--create_source_map ./script-min.js.map
--source_map_format=V3
--js_output_file script-min.jsThe two important command flags are --create_source_map and --source_map_format. This is required as the default version is V2 and we only want to work with V3.
The anatomy of a source map
In order to better understand a source map we’ll take a small example of a source map file that would be generated by the Closure compiler and dive into more detail on how the “mappings” section works. The following example is a slight variation from the V3 spec example.
{
version : 3,
file: "out.js",
sourceRoot : "",
sources: ["foo.js", "bar.js"],
names: ["src", "maps", "are", "fun"],
mappings: "AAgBC,SAAQ,CAAEA"
}Above you can see that a source map is an object literal containing lots of juicy info:
- Version number that the source map is based off
- The file name of the generated code (Your minifed/combined production file)
- sourceRoot allows you to prepend the sources with a folder structure – this is also a space saving technique
- sources contains all the file names that were combined
- names contains all variable/method names that appear throughout your code.
- Lastly the mappings property is where the magic happens using Base64 VLQ values. The real space saving is done here.
Base64 VLQ and keeping the source map small
Originally the source map spec had a very verbose output of all the mappings and resulted in the sourcemap being about 10 times the size of the generated code. Version two reduced that by around 50% and version three reduced it again by another 50%, so for a 133kB file you end up with a ~300kB source map. So how did they reduce the size while still maintaining the complex mappings?
VLQ (Variable Length Quantity) is used along with encoding the value into a Base64 value. The mappings property is a super big string. Within this string are semicolons (;) that represent a line number within the generated file. Within each line there are commas (,) that represent each segment within that line. Each of these segments is either 1, 4 or 5 in variable length fields. Some may appear longer but these contain continuation bits. Each segment builds upon the previous, which helps reduce the file size as each bit is relative to its previous segments.

Like I mentioned above each segment can be 1, 4 or 5 in variable length. This diagram is considered a variable length of four with one continuation bit (g). We’ll break down this segment and show you how the source map works out the original location. The values shown above are purely the Base64 decoded values, there is some more processing to get their true values. Each segment usually works out five things:
- Generated column
- Original file this appeared in
- Original line number
- Original column
- And if available original name.
Not every segment has a name, method name or argument, so segments throughout will switch between four and five variable length. The g value in the segment diagram above is what’s called a continuation bit this allows for further optimisation in the Base64 VLQ decoding stage. A continuation bit allows you to build on a segment value so you can store big numbers without having to store a big number, a very clever space saving technique that has its roots in the midi format.
The above diagram AAgBC once processed further would return 0, 0, 32, 16, 1 – the 32 being the continuation bit that helps build the following value of 16. B purely decoded in Base64 is 1. So the important values that are used are 0, 0, 16, 1. This then lets us know that line 1 (lines are kept count by the semi colons) column 0 of the generated file maps to file 0 (array of files 0 is foo.js), line 16 at column 1.
To show how the segments get decoded I will be referencing Mozilla’s Source Map JavaScript library. You can also look at the WebKit dev tools source mapping code, also written in JavaScript.
In order to properly understand how we get the value 16 from B we need to have a basic understanding of bitwise operators and how the spec works for source mapping. The preceding digit, g, gets flagged as a continuation bit by comparing the digit (32) and the VLQ_CONTINUATION_BIT (binary 100000 or 32) by using the bitwise AND (&) operator.
32 & 32 = 32
// or
100000
|
|
V
100000This returns a 1 in each bit position where both have it appear. So a Base64 decoded value of 33 & 32 would return 32 as they only share the 32 bit location as you can see in the above diagram. This then increases the the bit shift value by 5 for each preceding continuation bit. In the above case its only shifted by 5 once, so left shifting 1 (B) by 5.
1 << 5 // 32
// Shift the bit by 5 spots
______
| |
V V
100001 = 100000 = 32That value is then converted from a VLQ signed value by right shifting the number (32) one spot.
32 >> 1 // 16
//or
100000
|
|
V
010000 = 16So there we have it: that is how you turn 1 into 16. This may seem an over complicated process, but once the numbers start getting bigger it makes more sense.
Potential XSSI issues
The spec mentions cross site script inclusion issues that could arise from the consumption of a source map. To mitigate this it’s recommended that you prepend the first line of your source map with “)]}” to deliberately invalidate JavaScript so a syntax error will be thrown. The WebKit dev tools can handle this already.
if (response.slice(, 3) === ")]}") {
response = response.substring(response.indexOf('n'));
}
As shown above, the first three characters are sliced to check if they match the syntax error in the spec and if so removes all characters leading up to the first new line entity (n).
sourceURL and displayName in action: Eval and anonymous functions
While not part of the source map spec the following two conventions allow you to make development much easier when working with evals and anonymous functions.
The first helper looks very similar to the //# sourceMappingURL property and is actually mentioned in the source map V3 spec. By including the following special comment in your code, which will be evaled, you can name evals so they appear as more logical names in your dev tools. Check out a simple demo using the CoffeeScript compiler.
//# sourceURL=sqrt.coffee

The other helper allows you to name anonymous functions by using the displayName property available on the current context of the anonymous function. Profile the following demo to see the displayName property in action.
btns[].addEventListener("click", function(e) {
var fn = function() {
console.log("You clicked button number: 1");
};
fn.displayName = "Anonymous function of button 1";
return fn();
}, false);

When profiling your code within the dev tools the displayName property will be shown rather than something like (anonymous). However displayName is pretty much dead in the water and won’t be making it into Chrome. But all hope isn’t lost and a much better proposal has been suggested called debugName.
As of writing the eval naming is only available in Firefox and WebKit browsers. The displayName property is only in WebKit nightlies.
Let’s rally together
Currently there is very lengthy discussion on source map support being added to CoffeeScript. Go check out the issue and add your support for getting source map generation added to the CoffeeScript compiler. This will be a huge win for CoffeeScript and its devoted followers.
UglifyJS also has a source map issue you should take a look at too.
Lot’s of tools generate source maps, including the coffeescript compiler. I consider this a moot point now.
The more tools available to us that can generate a source maps the better off we’ll be, so go forth and ask or add source map support to your favourite open source project.
It’s not perfect
One thing Source Maps doesn’t cater for right now is watch expressions. The problem is that trying to inspect an argument or variable name within the current execution context won’t return anything as it doesn’t really exist. This would require some sort of reverse mapping to lookup the real name of the argument/variable you wish to inspect compared to the actual argument/variable name in your compiled JavaScript.
This of course is a solvable problem and with more attention on source maps we can start seeing some amazing features and better stability.
Issues
Recently jQuery 1.9 added support for source maps when served off of offical CDNs. It also pointed a peculiar bug when IE conditional compilation comments (//@cc_on) are used before jQuery loads. There has since been a commit to mitigate this by wrapping the sourceMappingURL in a multi-line comment. Lesson to be learned don’t use conditional comment.
This has since been addressed with the changing of the syntax to //#.
Tools and resource
Here’s some further resources and tools you should check out:
- Nick Fitzgerald has a fork of UglifyJS with source map support
- Paul Irish has a handy little demo showing off source maps
- Check out the WebKit changeset of when this dropped
- The changeset also included a layout test which got this whole article started
- Mozilla has a bug you should follow on the status of source maps in the built-in console
- Conrad Irwin has written a super useful source map gem for all you Ruby users
- Some further reading on eval naming and the displayName property
- You can check out the Closure Compilers source for creating source maps
- There are some screenshots and talk of support for GWT source maps
- Mozilla has a wiki entry on CSS Source Maps
Source maps are a very powerful utility in a developer’s tool set. It’s super useful to be able to keep your web app lean but easily debuggable. It’s also a very powerful learning tool for newer developers to see how experienced devs structure and write their apps without having to wade through unreadable minified code. What are you waiting for? Start generating source maps for all projects now!